Ce documentaire aborde en détail les différents mythes et procédures sur lesquels reposent la théorie scientifique des germes pathogènes, prétendument à l’origine de phénomènes de contagion, aussi appelée théorie des germes ou théorie microbienne.
L’histoire des épidémies telle que la poliomyélite, la variole et la grippe espagnole est retracée et le jargon des virologues et leurs techniques comme la PCR, le séquençage, l’effet cytopathique, le microscope électronique, les cultures cellulaires, l’isolement, la purification ou encore le concept d’anticorps sont analysés pour mieux comprendre sur quoi repose la virologie moderne et la théorie des germes dans son ensemble.
Le Dr Michael Yeadon, ancien directeur scientifique et vice-président de Pfizer, confirme sa conviction que les virus respiratoires n’existent pas.
J’ai réalisé, au fil du temps, que je ne pouvais plus maintenir ma compréhension des virus respiratoires telle que je pensais les connaître. Et puis j’ai appris de nouvelles informations récemment, et c’était juste, ça a effondré la possibilité que les virus respiratoires tels que décrits existent, ils n’existent pas.
Cette vidéo est le cinquième épisode de la série réalisée avec le média Kairos.
Dans le premier épisode, nous avons vu qu’il n’y a eu aucune hécatombe nulle part en Europe, ni en 2020, ni en 2021.
Dans le deuxième épisode nous avons vu qu’il n’y a pas eu la saturation hospitalière annoncée.
Dans le troisième épisode nous avons vu qu’il n’y a pas non plus eu un « déferlement » de malades. Il y a eu bien moins de malades comptabilisés que pendant les épisodes dit « grippaux » du passé. Nous vivons une épidémie de « cas » entretenue par les fameux « tests » qui n’ont pas de rapport avec la moindre maladie.
Dans le quatrième épisode nous avons vu le moteur même de la fraude : l’utilisation de codes spécifiques par les hôpitaux de façon à produire les « bonnes » statistiques.
Dans ce cinquième épisode nous découvrons le socle de l’idéologie sanitaire actuelle qui ne repose sur aucune expérience et est contredite par les statistiques : la contamination.
Via : https://nouveau-monde.ca/le-mythe-de-la-contamination-epidemique/
“La variole du singe” – qui aurait pu le voir venir ? Eh bien, apparemment, l’organisation fondée par Ted Turner en 2001, appelée “Nuclear Threat Initiative” (NTI), l’a vu venir lorsqu’elle a publié un rapport en novembre 2021 intitulé “Strengthening Global Systems to Prevent and Respond to High-Consequence Biological Threats” (Renforcer les systèmes mondiaux de prévention et de réponse aux menaces biologiques à haut risque). Le rapport indique qu’en mars 2021, ils se sont associés à la Conférence sur la sécurité de Munich pour réaliser un scénario d’exercice impliquant une “pandémie mondiale mortelle impliquant une souche inhabituelle du virus de la variole du singe qui est apparue dans la nation fictive de Brinia et s’est répandue dans le monde entier en 18 mois… la pandémie fictive a entraîné plus de trois milliards de cas et 270 millions de décès dans le monde.”
“Renforcer les systèmes mondiaux pour prévenir et répondre aux menaces biologiques de haute gravité
Résultats de l’exercice sur table 2021 mené en partenariat avec la en partenariat avec la Conférence de Munich sur la sécurité”
Étonnamment, le scénario prévoyait l’apparition de l’épidémie de variole du singe à la suite d’un acte de bioterrorisme en mai 2022, là où nous en sommes aujourd’hui. Nous avons traité de l’absurdité du gain de fonction[eng sub] impliquant des virus inexistants dans plusieurs autres vidéos[eng sub], et le Dr Stefan Lanka a également démantelé de tels raisonnements fallacieux. Quoi qu’il en soit, le rapport du NTI suggère que ce qu’il faut faire en cas d’épidémie imaginaire, ce sont “des mesures agressives pour ralentir la transmission du virus en empêchant les rassemblements de masse, en imposant des mesures de distanciation sociale et en mettant en place des obligations de port de masque.” Les pays gagnants dans l’hallucination du NTI ont mis en œuvre “des opérations de dépistage et de recherche des contacts à grande échelle et ont renforcé leurs systèmes de soins de santé”.
“Mais, je n’ai pas de virus Peter.”
Leurs graphiques, qui semblent avoir été produits par la calculatrice de Neil Ferguson, montrent que les pays qui ne se conforment pas à leurs restrictions et à leurs interventions médicales s’en sortiront bien plus mal. Le rapport poursuit en affirmant que “tant le scénario de l’exercice que la réponse de COVID-19 démontrent que les actions précoces des gouvernements nationaux ont des impacts positifs significatifs dans la gestion de l’impact de la maladie.” Quand on parle d'”impacts positifs”, on ne sait pas très bien qui est le bénéficiaire, bien qu’on note que “le marché du vaccin COVID dépassera 150 milliards de dollars en 2021.” Dans l’ensemble, le rapport du NTI se lit comme l’Event 201 sous Ritalin. (L’Event 201 a eu lieu le 18 octobre 2019. Il s’agissait d’un exercice impliquant une ” pandémie de coronavirus “, quelques mois seulement avant que la “pandémie” de COVID-19 ne soit déclarée).
La variole du singe attaque juste au bon moment !
https://www.nti.org/wp-content/uploads/2021/11/NTI_Paper_BIO-TTX_Final.pdf
Comme pour le COVID-19, il semble que d’autres parties aient également attendu avec impatience le marché que représenterait une telle “pandémie”. De même, ces voyants préparaient des vaccins pour aller là où aucun vaccin n’était allé auparavant. En l’occurrence, la société de biotechnologie Bavarian Nordic a obtenu l’approbation de la FDA en 2019 pour commercialiser JYNNEOS, un vaccin contre la variole et la variole du singe. D’autres autorités sanitaires ont également été amorcées pour réagir à une condition auparavant rare qui n’a pas préoccupé leurs nations… jusqu’à présent apparemment. Par exemple, le 20 mai 2022, l’Agence britannique de sécurité sanitaire a publié un document intitulé “Recommandations pour l’utilisation de la vaccination avant et après exposition lors d’un incident lié à la variole du singe.” Comme pour le COVID-19, on commence à avoir l’impression que toutes les routes mènent à nouveau aux vaccins….
Ce n’est qu’une question de temps avant que le vaccin “rare” contre la variole du singe n’arrive dans votre quartier.
Maintenant que le décor est planté, nous pouvons entrer dans la “science” de la variole du singe, en commençant par une description officielle de cette prétendue maladie virale. Selon le CDC, “la variole du singe a été découverte en 1958 lorsque deux épidémies d’une maladie ressemblant à la variole se sont déclarées dans des colonies de singes élevés pour la recherche, d’où le nom de “variole du singe”. Le premier cas humain de variole du singe a été enregistré en 1970 en République démocratique du Congo.” Ils poursuivent en affirmant que, “chez l’homme, les symptômes de la variole du singe sont similaires à ceux de la variole, mais plus légers.” La maladie ressemblerait à la grippe, avec en plus un gonflement des ganglions lymphatiques, puis le développement d’une éruption cutanée, et enfin des lésions qui évoluent de macules en vésicules puis en croûtes.
En ce qui concerne la létalité de la variole du singe, le CDC déclare que “en Afrique, il a été démontré que la variole du singe peut causer la mort d’une personne sur dix qui contracte la maladie”. Ce taux de létalité de 10 % a déjà alimenté le discours de peur et a également été utilisé comme taux de létalité dans le scénario catastrophe du NTI sur la variole du singe. Il convient de noter qu’historiquement, la variole du singe est pratiquement inconnue dans les pays développés et que les rares cas concernent généralement des personnes récemment arrivées d’Afrique.
En effet, l’une des seules “épidémies” de variole du singe enregistrées dans les pays développés a eu lieu aux États-Unis en avril 2003. Des cas ont été déclarés dans 6 États et seraient causés par des rongeurs importés du Ghana au Texas. C’était la première fois que la variole du singe était signalée en dehors de l’Afrique et le CDC a publié en 2006 un document analysant l’incident. Ce document indique que “la propagation du virus de personne à personne se ferait principalement par le biais d’exsudats oropharyngés infectieux”, bien qu’il soit clair que cela n’a jamais été scientifiquement établi. Ils continuent à dire que “le virus aurait été transmis par des animaux africains” – en d’autres termes, c’est une autre histoire d’agent pathogène qui saute d’une espèce à l’autre.
Ils ont rapporté que “les personnes dont la maladie s’est déclarée dans les 21 jours suivant l’exposition au MPXV [virus de la variole du singe] et qui ont présenté de la fièvre (définie comme une température corporelle supérieure à 37,4°C) et une éruption vésiculaire pustuleuse ou une éruption (potentiellement non caractérisée) ainsi que des anticorps IgM anti-virus orthopox ont été classées comme des cas probables d’infection”. Selon notre définition, 37,4°C n’est pas une fièvre, c’est une température corporelle normale et nous pensons que 37,6°C et plus sont considérés comme une fièvre. Nous avons noté dans leur tableau qu’ils utilisaient la classification ≥39,4°C, mais cela semble être une erreur car dans un autre article, que nous aborderons bientôt, il s’agissait à nouveau de 37,4°C. Le second article indique même que la “fièvre” peut être subjective. Il semble donc qu’ils utilisent ces critères peu rigoureux et pathologisent un état normal. En outre, le rapport hebdomadaire du CDC du 11 juillet 2003 indique que sur un total de 71 cas, seuls “deux patients, tous deux des enfants, présentaient une maladie clinique grave ; ces deux patients se sont rétablis”. Les autres patients présentaient divers symptômes respiratoires et gastro-intestinaux.
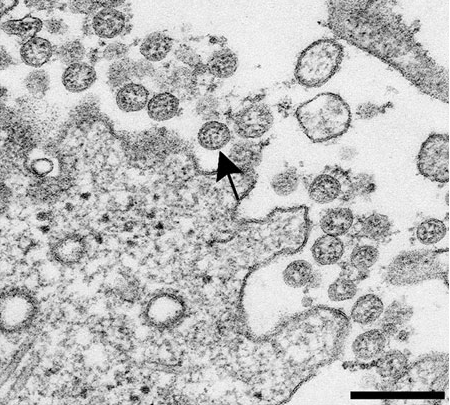
Selon le CDC, les cas ont été confirmés sur la base d’échantillons présentant “l’isolement du virus de la variole du singe, la détection de signatures d’acides nucléiques spécifiques de la variole du singe, des résultats positifs en microscopie électronique ou des résultats positifs en immunohistochimie.” Nous avons examiné les micrographies électroniques présentées par le CDC, notamment l’image ci-dessous d’un échantillon de peau provenant de l’un des patients. La légende nous informe que les particules rondes à droite sont des virions immatures de la variole du singe, tandis que les particules ovales à gauche sont des virus matures. Cependant, il ne s’agit que d’une image statique de tissu mort et aucune conclusion ne peut être tirée quant au rôle biologique des particules imagées. Aucune d’entre elles ne s’est avérée être un parasite intracellulaire pathogène capable de se répliquer et ne devrait donc être appelée “virus”.
En examinant à nouveau le rapport hebdomadaire du CDC de 2003, il apparaît que les 35 “cas confirmés en laboratoire” ont tous fait l’objet de “tests” de réaction en chaîne par polymérase (PCR), et nous avons donc cherché les preuves scientifiques derrière cette affirmation. L’une des citations pour le développement de la détection de la variole du singe par PCR est un article de 2004 intitulé “Real-Time PCR System for Detection of Orthopoxviruses and Simultaneous Identification of Smallpox Virus” (Système PCR en temps réel pour la détection des orthopoxvirus et l’identification simultanée du virus de la variole). Or, un protocole PCR nécessite de connaître les séquences génétiques du prétendu virus de la variole du singe, ce qui nous amène à cet article de 2001 intitulé “Human monkeypox and smallpox viruses : genomic comparison” (Virus de la variole du singe et de la variole humaine : comparaison génomique). Cet article prétendait avoir “isolé” le virus de la variole du singe dans une culture de cellules rénales de singe rhésus provenant d’une croûte d’un patient atteint de la variole du singe. Ici, les virologues reprennent leurs vieux tours en affirmant que : (a) la croûte du patient contient le virus de la variole du singe, et (b) il se trouve maintenant dans leur culture. Ils prétendent avoir séquencé le “génome viral” en se référant à un processus décrit pour le séquençage d’un prétendu virus variolique en 1993.
Mais lorsque nous examinons cet article, aucun virus n’est démontré non plus, simplement une affirmation selon laquelle il a été “isolé” à partir “du matériel d’un patient indien” en 1967. Ils poursuivent en affirmant que “les virions ont été purifiés par centrifugation différentielle et l’ADN viral a été isolé” – cependant, il n’y a aucune démonstration de ce qu’ils ont purifié ou de la façon dont ils ont été déterminés comme étant des virions. Dans aucune de ces expériences, ils n’ont procédé à des contrôles pour voir quelles séquences peuvent être détectées à partir d’autres croûtes d’origine humaine ou de spécimens similaires provenant de personnes malades. C’est ici qu’il faut rappeler aux virologues ce qu’est censé être un virus, c’est-à-dire un parasite intracellulaire capable de se répliquer qui infecte et provoque une maladie chez un hôte. Il ne s’agit pas de détecter des séquences génétiques contenues dans des croûtes et de prétendre qu’elles appartiennent à un virus.
Pour en revenir à l’article du CDC décrivant l'”épidémie” de 2003, il n’est pas clair comment ils ont établi qu’ils pouvaient diagnostiquer la variole du singe en utilisant la PCR. Leur PCR ne peut avoir été calibrée que sur des séquences de provenance indéterminée. En outre, peu importe le type de spécificité analytique de leur protocole PCR, il n’y avait pas de spécificité diagnostique établie – en d’autres termes, il ne s’agissait pas d’un test validé cliniquement, une question qui va au-delà de l’existence ou non du “virus”. (Extrait des directives de la MIQE : La spécificité analytique fait référence au fait que le test qPCR détecte la séquence cible appropriée plutôt que d’autres cibles non spécifiques également présentes dans un échantillon. La spécificité diagnostique est le pourcentage d’individus sans une condition donnée que le test identifie comme négatif pour cette condition).
Les 47 cas américains qu’ils ont fini par décrire ont tous été en contact, d’une manière ou d’une autre, avec des chiens de prairie [rongeurs] africains importés et l’article du CDC conclut que “les individus ont contracté des infections par le MPXV à partir de chiens de prairie infectés ; aucune transmission interhumaine n’a été documentée, mais il y avait de nombreux scénarios potentiels d’infection impliquant des expositions respiratoires et/ou muco-cutanées, des expositions percutanées et/ou par inoculation”. Les auteurs de l’étude ont admis que la conception de l’étude présentait certains problèmes, notamment que “les analyses étaient limitées par la déclaration ou le rappel incomplet des informations par les patients. Et, en raison de la nature rétrospective de l’étude, nous n’avons pas été en mesure d’obtenir des données très détaillées.”
Cependant, même en leur laissant une certaine marge de manœuvre, les incohérences vont encore plus loin. Tout d’abord, personne dans l’incident américain n’est mort de la maladie dont le taux de létalité serait de 10% en Afrique. Il ne fait aucun doute que les taux de létalité incohérents seront attribués à différents “variants”, mais il ne peut y avoir de variants de quelque chose qui n’existe pas.
Peu d’images des lésions cutanées signalées lors de l’incident de 2003 étaient disponibles, mais deux des cas américains sont décrits ci-dessous et une image d’un cas de variole du singe en Afrique est présentée à titre de comparaison. Le lecteur peut se faire sa propre opinion, mais ces réactions cutanées ne nous semblent pas du tout comparables.
Enfant africain atteint de la variole du singe
Un enfant américain atteint de la variole du singe
Un homme américain atteint de la variole du singe
Ensuite, le CDC affirme que “le réservoir naturel de la variole du singe reste inconnu. Cependant, les rongeurs africains et les primates non humains (comme les singes) peuvent héberger le virus et infecter des personnes” – en d’autres termes, tout cela est plutôt vague et reste une hypothèse non prouvée. Il est évident que certaines personnes ont été malades aux États-Unis en 2003, mais avec la théorie virale, nous sommes censés croire que le virus est passé de certains chiens de prairie à certains humains et que ces derniers ont été infectés par le prétendu virus… mais alors aucun humain ne pourrait le transmettre à un autre humain. La théorie tombe à plat – un virus doit se propager. Et les schémas historiques des prétendues épidémies de variole du singe n’ont aucun sens – pourquoi le virus est-il transmis à ces personnes si facilement, alors qu’il peut s’écouler une décennie entre les prétendues “épidémies” ?
Malheureusement, l’incident de 2003 a été étudié comme si la théorie de la contagion virale était déjà établie et les autres explications ont été ignorées. Si des personnes sont censées tomber malades à cause de ces rongeurs africains, ne serait-il pas judicieux de vérifier que les animaux ne présentent pas d’autres toxicités, notamment dans leurs excréments, et qu’ils ne sont pas porteurs de tiques ou de parasites ? Nous avons remarqué qu’une autre référence indique que, en ce qui concerne les cas américains, “de nombreuses personnes présentaient des lésions initiales et satellites sur les paumes, les plantes et les extrémités.” Cependant, selon le CDC, la variole du singe commence généralement sur le visage, de sorte que le tableau clinique des cas américains ne correspond pas aux cas généralement décrits en Afrique.
Quoi qu’il en soit, un examen des preuves scientifiques a révélé qu’en ce qui concerne la variole du singe : (a) il n’y a aucune preuve de l’existence d’une particule physique répondant à la définition d’un virus, (b) il n’y a aucune preuve de transmission entre humains et (c) il n’y a aucun moyen de confirmer un diagnostic de variole du singe à moins de croire à des tests cliniquement non validés tels que les kits PCR qui ont été produits. En d’autres termes, si nous assistons à une “pandémie” de variole du singe qui sert de prétexte à l’intensification du terrorisme mondialiste, ce sera à la suite d’une autre pandémie de PCR, et non d’une pandémie naturelle.
Pour ceux d’entre vous qui souhaitent approfondir les problèmes posés par les diverses allégations relatives à la variole du singe, Mike Stone, de ViroLIEgy, a rédigé deux articles intéressants. Le premier article, intitulé “La variole a-t-elle vraiment été éradiquée ?“[FR], traite notamment de l’émergence opportune de la variole du singe alors que la variole était apparemment en voie d’éradication. Le deuxième article s’intitule “Did William Heberden Distinguish Chickenpox From Smallpox in 1767?” (William Heberden a-t-il distingué la varicelle de la variole en 1767 ?). Il souligne le fait que les affections liées à la variole ne sont pas aussi faciles à distinguer les unes des autres que le suggèrent les manuels scolaires et semblent davantage liées à la gravité d’un processus pathologique similaire. Vous pouvez également regarder notre vidéo “Chickenpox Parties and Varicella Zoster Virus?” (Les pox party et le virus varicelle-zona ?) pour voir pourquoi il n’y a pas non plus de preuve de la présence d’un virus dans cette affection connexe.
Du point de vue de la théorie du terrain, c’est une erreur fondamentale d’attribuer la maladie d’une personne à un supposé virus, car les “traitements” qui s’ensuivent ne traitent pas les problèmes sous-jacents. Si quelqu’un ne va pas bien, c’est généralement parce qu’il a une carence en nutriments et qu’il doit rétablir l’équilibre, ou parce qu’il a été exposé à des toxines environnementales et qu’il doit aider son corps à se désintoxiquer. Les guerres contre de prétendus agents pathogènes, qui impliquent de traiter tout le monde de la même manière avec des restrictions des droits civiques et des vaccins, ne relèvent certainement pas de la santé. Il est bon de voir que de plus en plus de personnes prennent conscience de la fraude du COVID-19[FR]. On peut donc espérer qu’une escroquerie à la variole du singe, si elle est tentée, apportera encore plus de lumière à la situation. Comme toujours, votre santé est entre vos mains, et non entre celles d’une secte mondialiste et de ses acolytes.
Article original (anglais) : https://drsambailey.com/viruses/monkeypox-mythology/
Plus de ressources : https://viroliegy.com/2022/05/24/monkey-business/
Le 8 mai 1980, l’Organisation mondiale de la santé (OMS) a annoncé l’éradication complète du “virus” de la variole dans le monde. Ce jour est considéré comme l’une des plus grandes réussites de la médecine moderne. L’humanité s’est unie dans un effort mondial et a finalement vaincu un ennemi mortel en utilisant le “miracle” médical de la vaccination. Cette réussite triomphante a été utilisée pour justifier toutes les campagnes de vaccination depuis lors. La disparition de la variole par le biais d’une injection meurtrière a été fortement mise en avant pour convaincre le public de l’utilité des vaccins expérimentaux à ARNm que l’on nous impose actuellement dans le cadre de la campagne de terreur ” SARS-COV-2 “.
Le 8 mai 1980, la variole a été officiellement déclarée éradiquée au niveau mondial.
Cependant, que se passe-t-il si l’éradication de la variole ne se vérifie pas dans les faits ? Et si les mêmes symptômes de la maladie connue sous le nom de variole existaient encore aujourd’hui ? Et si ces symptômes n’avaient jamais disparu et avaient reçu de nouveaux noms et identités ? Et si les vaccins utilisés pour éradiquer ce “virus” provoquaient en fait les mêmes symptômes que la variole, voire pire ?
Voyons ce que nous pouvons découvrir sur cette prétendue éradication de l’une des “maladies les plus mortelles de tous les temps”.
L’appel de 1958 pour l’éradication mondiale de la variole
En 1958, alors qu’un vaccin contre la variole était utilisé depuis plus d’un siècle et que la prévalence de la maladie avait déjà diminué, l’OMS a décidé qu’il était enfin temps de faire pression pour l’éradication du “virus”. L’objectif était de créer une infrastructure de vaccination dans le monde entier afin d’éradiquer cette maladie une fois pour toutes. Heureusement pour les grands pays comme les États-Unis, la variole avait déjà disparu. Ce sont les petits pays qui ont eu besoin que les États-Unis et l’Union soviétique interviennent et fournissent 150 millions de doses de vaccins pour assurer la victoire.
Vaccin contre la variole : Le bon, la brute et le truand
“Le premier grand effort d’éradication de la variole a été lancé en 1950 dans le but d’éliminer la variole dans les Amériques. En 1958, l’Assemblée mondiale de la santé a adopté une résolution appelant à l’éradication mondiale de la variole. Bien que certains pays aient mis en place des programmes d’éradication de la variole, il n’existait aucune infrastructure coordonnée. De nombreux programmes ont échoué en raison d’un approvisionnement insuffisant en vaccins et de ressources limitées. La forme la plus virulente de la variole, la variole majeure, était répandue aux États-Unis au XIXe siècle, mais seules deux grandes épidémies ont eu lieu entre 1900 et 1925. En revanche, la forme plus bénigne de la variole (variola minor) était courante jusque dans les années 1930. Après 1949, il n’y a plus eu de cas endémiques de variole aux États-Unis, mais la maladie est restée un problème grave dans les pays moins développés. En 1966, la variole restait endémique dans 33 pays. Après un long débat, l’Assemblée mondiale de la santé a approuvé l’octroi de 2,4 millions de dollars pour lancer un programme mondial d’éradication au cours des dix années suivantes. Au début de la campagne, l’Union soviétique et les États-Unis ont fait don de plus de 150 millions de doses de vaccin. À peu près à la même époque, l’aiguille bifurquée a été mise au point, ce qui a simplifié l’administration et réduit le volume de vaccin nécessaire.“
Comme le montre l’OMS en 1958, la vaccination de la population contre la variole fait l’objet d’une pression accrue, en particulier dans les pays les plus pauvres. Ces efforts ont été déployés malgré l’échec des campagnes de vaccination répétées dans certaines régions et malgré les dangers connus liés à l’utilisation du vaccin. L’OMS a demandé une vaccination supplémentaire et la revaccination de certaines populations. En d’autres termes, l’OMS a préconisé une campagne de vaccination de masse avec des rappels tout en demandant des études de sécurité sur les vaccins eux-mêmes. Cela vous rappelle-t-il quelque chose ?
Un vaccin dangereux
Quand le vaccin est plus mortel que la menace d’un “virus éradiqué”.
Alors qu’il semblait que la sécurité des vaccins était encore remise en question en 1958, nous avons la chance, avec le recul, de voir quels types d’effets dévastateurs ont finalement été découverts à long terme.
LES EFFETS INDÉSIRABLES DE LA VACCINATION
Fréquence et caractères cliniques
“Le vaccin antivariolique est moins sûr que les autres vaccins utilisés couramment aujourd’hui. Le vaccin est associé à des effets indésirables connus qui vont de légers à graves. Les réactions légères au vaccin comprennent la formation de lésions satellites, de la fièvre, des douleurs musculaires, une lymphadénopathie régionale, de la fatigue, des maux de tête, des nausées, des éruptions cutanées et une douleur au site de vaccination.13,18,19 Un essai clinique récent a rapporté que plus d’un tiers des personnes vaccinées ont manqué des jours de travail ou d’école en raison de ces symptômes légers liés au vaccin.18”
“En revanche, la plupart des personnes qui reçoivent le vaccin contre la variole ou la variole du singe n’ont que des réactions mineures, comme une légère fièvre, de la fatigue, des glandes enflées, des rougeurs et des démangeaisons à l’endroit où le vaccin est administré. Toutefois, ces vaccins présentent également des risques plus graves.
Sur la base de l’expérience passée, on estime qu’entre 1 et 2 personnes sur 1 million de personnes vaccinées mourront à la suite de complications potentiellement mortelles liées au vaccin.”
Il semblerait que les seuls symptômes des réactions légères au vaccin antivariolique soient la maladie elle-même. À cela s’ajoute la probable sous-estimation par le CDC des décès associés au vaccin.
En 2003, le président Bush a pris la décision de rendre la vaccination contre la variole obligatoire pour tout le personnel militaire et de recommander le vaccin à un demi-million de professionnels de santé. Bien que la variole ait été déclarée éradiquée au niveau mondial 23 ans avant la décision de Bush Jr. et que la maladie elle-même ait été considérée comme non endémique aux États-Unis depuis 1949, la menace que le “virus” éradiqué soit utilisé comme arme biologique a été utilisée pour justifier cette décision. Les reportages de CBS de l’époque dressent un tableau très négatif du vaccin :
” Le vaccin a été créé en 1796. Le vaccin utilisé aujourd’hui est essentiellement le même, dit Mme Offit. “Nous avons tendance à penser que les vaccins sont très sûrs et tous efficaces, ce qu’ils sont. Mais tous les vaccins que nous utilisons aujourd’hui sont le fruit de la technologie moderne. Ce n’est pas le cas du vaccin antivariolique. Il présente un profil d’effets secondaires que nous n’accepterions pas pour les vaccins d’aujourd’hui”, ajoute-t-il.
Alors que l’OMS a lancé un appel mondial à l’éradication de la variole en 1958, les “poxvirus” n’ont apparemment pas reçu le mémo car un autre événement curieux s’est produit cette année-là : la découverte de la variole du singe. Il s’agissait d’une nouvelle maladie qui rappelait étrangement la variole et qui était censée ne toucher que les singes en captivité utilisés à des fins d’expérimentation. Cependant, douze ans après sa découverte et une décennie avant la déclaration de l’éradication de la variole, la variole du singe a décidé de passer de l’animal à l’homme. Bien sûr, le fait que ce “virus” identique à celui de la variole dans tous les domaines ait sauté du navire pour infecter les humains au plus fort de la campagne de vaccination contre la variole n’est qu’une “coïncidence”. Ou se pourrait-il que les mêmes symptômes de maladie associés à la variole aient été renommés, réétiquetés et vendus comme une nouvelle maladie afin de donner l’apparence d’une campagne d’éradication réussie ? Ils l’ont déjà fait avec la varicelle, comme je l’ai expliqué ici :
Il n’est pas difficile de voir que le même tour a été joué ici avec la variole du singe. Deux sources permettent de montrer les étonnantes similitudes entre ces “virus” prétendument distincts. La première provient directement de l’OMS.
Comme le montrent les informations fournies par l’OMS, la variole du singe et la variole sont exactement la même maladie. Elles présentent les mêmes symptômes, le même mode de transmission, le même vaccin et la même réponse théorique des anticorps. La seule différence revendiquée par l’OMS est que la variole du singe est estimée moins mortelle que la variole et qu’elle provient d’un animal de source inconnue alors que la variole ne se trouve que chez l’homme. Ces deux différences sont d’ailleurs théoriques.
Si l’OMS n’était pas suffisamment convaincante quant à la nature identique de ces deux maladies, des extraits du classique de 1988 Smallpox and its Eradication de Frank Fenner, pourraient convaincre. Extrait du chapitre 29 de ce document de près de 1800 pages :
“La variole du singe chez l’homme a été reconnue pour la première fois en 1970 ; il s’agit d’une maladie systémique grave avec une éruption pustulaire généralisée, que l’on ne peut distinguer cliniquement de la variole. Outre les virus de la variole et de la variole du singe, 7 autres espèces de poxvirus, appartenant à 4 genres, peuvent provoquer des lésions chez l’homme (Tableau 29.1). Bien que l’infection par chacun de ces virus produise tout au plus des symptômes légers et généralement seulement une lésion cutanée localisée, les maladies en question ont présenté un problème de diagnostic potentiel lors de l’éradication mondiale de la variole, car les particules virales trouvées dans les lésions par examen au microscope électronique pouvaient être confondues avec celles du virus variolique.”
“La découverte de la variole du singe humaine en Afrique centrale en septembre 1970 a été suivie de la démonstration que 4 cas de variole présumée au Libéria et 1 cas en Sierra Leone en 1970, et 1 cas chacun au Nigeria et en Côte d’Ivoire en 1971 (Foster et al ., 1972) étaient des cas de variole du singe humaine (Lourie et al ., 1972). Une série d’études coordonnées en laboratoire et sur le terrain a été organisée pour déterminer l’incidence de la maladie, étudier ses caractéristiques cliniques et son épidémiologie et rechercher le ou les réservoirs animaux du virus.”
Il est clair que la variole du singe et la variole présentent exactement les mêmes symptômes. On dit que la variole du singe est cliniquement indiscernable de la variole. Il est impossible de les différencier sous microscope électronique car les particules sont exactement les mêmes. Il a été admis que si un réservoir animal de variole était découvert, il ne pourrait pas être éradiqué. Ainsi, au lieu de prétendre que le “virus” de la variole infectait aussi bien les animaux que les humains, ce qui aurait détruit l’histoire de l’éradication, un nouveau “virus” a été créé afin de dire qu’un “virus” identique était passé de l’animal à l’homme. C’est ainsi qu’ils peuvent s’en sortir lorsqu’ils disent que la variole a été éradiquée tout en affirmant que la même maladie existe mais qu’elle est causée par un “virus” différent. Ainsi, les virologues peuvent avoir le beurre et l’argent du beurre.
La lymphadénopathie est-elle spécifique de la variole du singe ?
Les virologues tentent toutefois de créer l’illusion qu’il s’agit de maladies distinctes causées par des “virus” différents en affirmant que la lymphadénopathie est une caractéristique déterminante de la variole du singe. Ils affirment que l’hypertrophie des ganglions lymphatiques est spécifique de la variole du singe et n’a pas été observée dans le cas de la variole. Cependant, cette histoire tombe à l’eau si la lymphadénopathie est également présente dans les cas de variole et ne l’est pas dans tous les cas de monkeypox. Jetons un coup d’œil et voyons si leur fiction tient la route :
Cette première source de novembre 2020 affirme que l’hypertrophie des ganglions lymphatiques n’est pas toujours présente dans les cas de monkeypox :
“Le monkeypox humain ressemble à la variole, avec une éruption cutanée et des signes constitutionnels, mais les symptômes sont généralement plus légers et, contrairement à la variole, les ganglions lymphatiques sont généralement (mais pas toujours) hypertrophiés. Le plus souvent, la maladie commence par des symptômes non spécifiques, semblables à ceux de la grippe, qui peuvent comprendre un malaise, de la fièvre, des frissons, des maux de tête, des maux de gorge, des myalgies, des maux de dos, de la fatigue, des nausées, des vomissements et une toux non productive. La lymphadénopathie peut être régionale ou généralisée et touche le plus souvent les ganglions lymphatiques submandibulaires, postauriculaires, cervicaux et/ou inguinaux.”
Alors que cette deuxième source de 2018 indique que le gonflement des ganglions lymphatiques n’est pas habituellement observé avec la variole, nous pouvons donc en déduire qu’il existe des cas où le gonflement des ganglions lymphatiques s’est produit :
Quels sont les symptômes de la variole du singe ?
“Chez l’homme, les signes et les symptômes de la variole du singe sont similaires à ceux de la variole, mais ils sont généralement plus légers. La variole du singe provoque de la fièvre, des maux de tête, des maux de dos, un gonflement des ganglions lymphatiques (qui n’est généralement pas observé dans le cas de la variole), des maux de gorge et de la toux.”
Les virologues avaient besoin d’un nouveau symptôme spécifique pour faire accepter l’idée que la variole du singe est en quelque sorte différente de la variole. Cependant, il semblerait, d’après ces sources, que le gonflement des ganglions lymphatiques ne soit pas toujours un symptôme de la variole et qu’il puisse également accompagner la variole. Ainsi, ce symptôme ne peut guère être considéré comme spécifique de la variole du singe ni comme un moyen de différencier les deux.
Comment peut-on alors prétendre que le gonflement des ganglions lymphatiques n’est pas une caractéristique de la variole ? S’agit-il vraiment d’un symptôme qui n’a pas été retrouvé dans les cas de la maladie ou se peut-il que l’adénopathie n’ait pas été recherchée lors de l’examen ? Une troisième source datant de 2012 soutient cette dernière hypothèse en affirmant que le gonflement des ganglions n’était pas bien décrit pour la variole, car très peu d’attention était portée à ce symptôme lors de l’examen. Cependant, une hypertrophie (agrandissement) et une hyperamélie (excès de sang) des glandes lymphatiques ont été notées dans les cas de variole. On disait que cette hypertrophie était due à une rétention d’eau. Il est également affirmé dans cette source que les cas de variole du singe ont très probablement été diagnostiqués comme des cas de variole (ou logiquement l’inverse) et que la variole du singe n’a même pas été reconnue comme une maladie distincte avant 1970, ce qui signifie qu’il s’agissait jusqu’alors de la même maladie :
“La pathologie des ganglions lymphatiques dans les cas de variole naturelle est mal décrite. Councilman et al. (1904) notent que dans la littérature antérieure au 20ème siècle, ‘très peu d’attention a été accordée à l’état des ganglions lymphatiques dans la variole’. Dans son étude de cas, Bras (1952) rapporte que les ganglions lymphatiques n’étaient pas examinés régulièrement et que leur description se limite à trois phrases. D’après les données disponibles, les modifications ganglionnaires brutes les plus fréquemment rapportées sont l’hypertrophie et l’hyperémie ; cependant, dans de nombreux cas, les ganglions lymphatiques sont apparemment normaux. Sur le plan histologique, l’hypertrophie, si elle est présente, semble être due principalement à un œdème et à une congestion. Councilman et al. (1904) déclarent spécifiquement que “l’élargissement du ganglion est plus dû à l’œdème qu’à l’hyperplasie cellulaire”. Une histiocytose sinusale et une hémorragie multifocale avec érythrophagocytose et fibrine abondante sont également rapportées. Comme pour la rate, de nombreux auteurs décrivent également de multiples foyers de nécrose et de lymphocytolyse, avec ou sans bactéries ; cependant, une association avec un type de maladie spécifique n’est pas toujours faite. Dans quelques rapports, la nécrose avec des bactéries intralésionnelles serait plus fréquente avec la maladie hémorragique.”
“Avant l’éradication de la variole, les infections humaines à MPXV étaient probablement diagnostiquées à tort comme des infections à VARV en raison de la prévalence de la variole et de la similitude de la présentation et de l’évolution de la maladie cutanée. Le monkeypox n’a pas été reconnu comme une maladie distincte de la variole jusqu’en 1970, lorsque l’élimination de la variole en République démocratique du Congo a révélé la persistance d’une maladie semblable à la variole (Fenner et al., 1988b).”
Il est clair que la lymphadénopathie n’est pas spécifique à la variole du singe, mais il peut y avoir une raison à l’augmentation de ce symptôme si c’est vraiment le cas. Dans la section précédente sur les effets secondaires de la vaccination antivariolique, la lymphadénopathie et le gonflement des glandes ont été mis en évidence comme des réactions connues à la vaccination. Ceci a été documenté par une étude sur les effets indésirables datant de 1968 :
“Le lymphandénite postvaccinal est l’expression désignant les modifications réactives qui se produisent dans les ganglions lymphatiques en réponse à une vaccination antivariolique.”
“De 1983 à 1991, 4649 doses de vaccin antivariolique ont été administrées, dont 57% en 1989-91. La proportion de primo-vaccinations est passée de 4% en 1983-88 à 14% en 1989-91. Parmi les personnes vaccinées, 93% n’ont signalé aucun signe ou symptôme après la vaccination. Les effets indésirables signalés étaient légers : lymphadénopathie, fièvre ou frissons, et sensibilité au site de vaccination. Aucun effet indésirable grave n’a été signalé. Cependant, une personne vaccinée a signalé un avortement spontané 5 mois après la primovaccination (16).”
Même le CDC connaissait cette réaction à la vaccination antivariolique et la considérait comme normale :
Les réactions normales qui ne nécessitent pas de traitement spécifique comprennent la fatigue, les céphalées, les myalgies, les lymphadénopathies régionales, la lymphangite, le prurit et l’œdème au site d’inoculation, ainsi que les lésions satellites, qui sont des lésions secondaires bénignes, proximales aux lésions centrales de la vaccination.
https://www.aafp.org/afp/2003/0415/p1827.html
Si l’on s’en tient aux faits, le vaccin antivariolique était connu pour provoquer une lymphadénopathie ainsi que tous les autres symptômes associés à la variole du singe et à la variole. Une campagne de vaccination de masse a été lancée dans les années 1950 et l’OMS a appelé à l’éradication mondiale de la variole en 1958. Par coïncidence, la variole du singe a également été découverte en 1958 chez des singes captifs utilisés pour des expériences de vaccination contre la polio. En 1970, un garçon du Zaïre, une région réputée exempte de variole depuis 1968, aurait été le premier cas humain de variole du singe, une maladie que l’on ne peut distinguer cliniquement de la variole, à l’exception du symptôme de lymphadénopathie, une réaction connue à la vaccination antivariolique et un symptôme négligé de la variole. Si l’on examine cette situation de manière critique et logique, il est facile de voir que l’apparition soudaine de la variole était la couverture parfaite pour l’OMS afin d’entretenir le mythe de l’éradication de la variole et de dissimuler les réactions indésirables à la vaccination.
En résumé :
Le premier grand effort d’éradication de la variole a été lancé en 1950 dans le but d’éliminer la variole dans les Amériques.
En 1958, l’Assemblée mondiale de la santé a adopté une résolution appelant à l’éradication mondiale de la variole.
Après 1949, il n’y a plus de cas endémiques de variole aux États-Unis, mais la maladie reste un problème grave dans les pays moins développés.
Au début de la campagne, l’Union soviétique et les États-Unis ont fait don de plus de 150 millions de doses de vaccin.
À peu près à la même époque, l’aiguille bifurquée a été mise au point, ce qui a simplifié l’administration et réduit le volume de vaccin nécessaire.
Dans ses notes de 1958, l’OMS admet le fait que la variole persiste dans certaines régions malgré les campagnes de vaccination répétées
Si l’OMS pousse à l’augmentation de la production de vaccins, elle demande également que soient étudiées les mesures à prendre pour éviter les complications qui pourraient résulter de la vaccination antivariolique.
Ils ont demandé à tous les gouvernements de vacciner, en 1959-1960, la population des pays dans lesquels existent les principaux foyers endémiques de variole.
Ils ont également déclaré qu’en 1961-1962, une vaccination supplémentaire de la population devrait être effectuée dans les foyers où la maladie persiste et que, par la suite, des revaccinations seraient effectuées dans la mesure où cela s’avérerait nécessaire, conformément à l’expérience acquise dans chaque pays.
Enfin, il a été demandé aux médecins et aux institutions scientifiques actives dans le domaine de la microbiologie et de l’épidémiologie de stimuler leurs efforts en vue d’améliorer la qualité et la technologie de la production d’un vaccin antivariolique satisfaisant et résistant à l’influence de la température.
En d’autres termes, l’OMS a préconisé une campagne de vaccination de masse avec des rappels tout en demandant des études de sécurité sur les vaccins eux-mêmes.
Le vaccin antivariolique est “moins sûr” que les autres vaccins couramment utilisés aujourd’hui.
Les réactions légères au vaccin comprennent : la formation de lésions satellites, fièvre, douleurs musculaires, lymphadénopathie régionale, fatigue, maux de tête, nausées, éruptions cutanées, douleur au site de vaccination.
Selon les estimations toujours “précises” du CDC, on estime qu’entre 1 et 2 personnes sur 1 million de vaccinés mourront à la suite de complications potentiellement mortelles liées au vaccin.
Le vaccin antivariolique est mortel et les scientifiques le qualifient de vaccin le plus dangereux connu de l’homme.
En 2003, l’administration Bush a rendu obligatoire la vaccination de tout le personnel militaire contre la variole et a recommandé aux professionnels de santé de recevoir le vaccin.
Cette mesure était motivée par la menace d’une utilisation d’un “virus” éradiqué comme arme biologique.
Le dilemme était décrit comme suit :
Ne pas vacciner la population contre la variole et laisser des millions de personnes vulnérables à l’un des pires fléaux connus de l’homme.
Ou traiter les gens avec un vaccin qui est extrêmement efficace pour bloquer la maladie mais qui peut provoquer des réactions dangereuses, parfois mortelles.
Le vaccin a été créé en 1796 et le vaccin utilisé aujourd’hui est essentiellement le même.
Le profil des effets secondaires du vaccin antivariolique ne serait pas accepté pour les vaccins actuels.
Le vaccin antivariolique est fabriqué à partir d’un cousin biologique faible du “virus” de la variole.
En 1958, le “virus” de la variole du singe a été découvert chez des primates en cage utilisés pour des expériences scientifiques et a fini par être transmis à l’homme en 1970.
Selon l’OMS, la présentation clinique de la variole du singe ressemble à celle de la variole.
La variole du singe est une zoonose “virale” (un “virus” transmis à l’homme par les animaux) dont les symptômes sont similaires à ceux observés dans le passé chez les patients atteints de variole.
La variole du singe a été identifiée pour la première fois chez l’homme en 1970, en République démocratique du Congo (alors appelée Zaïre), chez un garçon de 9 ans, dans une région où la variole avait été éliminée (comme par hasard) en 1968.
Malgré son nom, le réservoir naturel de la variole du singe n’a pas encore été identifié, mais les rongeurs seraient le plus probable.
Le diagnostic différentiel clinique à prendre en compte comprend d’autres maladies à éruptions cutanées, telles que la varicelle, la rougeole, les infections cutanées bactériennes, la gale, la syphilis et les allergies liées aux médicaments.
La lymphadénopathie (nous y reviendrons plus tard) pendant la phase prodromique de la maladie peut être une caractéristique clinique permettant de distinguer la variole du singe de la varicelle ou de la variole.
La réaction en chaîne par polymérase (PCR) est le test de laboratoire privilégié en raison de sa précision et de sa sensibilité.
Pour cela, les échantillons optimaux pour le diagnostic de la variole du singe proviennent des lésions cutanées – le toit ou le liquide des vésicules et des pustules, et les croûtes sèches.
Les tests sanguins PCR ne sont généralement pas concluants en raison de la courte durée de la virémie par rapport au moment du prélèvement de l’échantillon après le début des symptômes et ne doivent pas être prélevés systématiquement sur les patients.
En d’autres termes, le “virus” est en quelque sorte présent dans les lésions cutanées mais pas dans le sang…
Les “orthopoxvirus” ayant une réactivité sérologique croisée, les méthodes de détection des antigènes et des anticorps ne permettent pas de confirmer la spécificité du virus de la variole du singe (c’est-à-dire qu’elles donneraient un résultat positif pour la variole ou tout autre “poxvirus”) et ne sont pas recommandées.
En outre, une vaccination récente ou lointaine avec le vaccin contre la variole (par exemple, toute personne vaccinée avant “l’éradication” de la variole, ou vaccinée plus récemment en raison d’un risque plus élevé) peut entraîner des résultats faussement positifs.
En d’autres termes, les anticorps sont une mesure inutile puisqu’ils indiquent qu’une personne est positive à la variole.
L’OMS admet à nouveau que la présentation clinique de la variole du singe ressemble à celle de la variole, une infection orthopoxvirale apparentée qui a été éradiquée dans le monde entier.
Elle déclare également que, bien que la variole n’existe plus à l’état naturel, le secteur mondial de la santé reste vigilant au cas où elle pourrait réapparaître par des mécanismes naturels, un accident de laboratoire ou une dissémination délibérée.
Dans l’ouvrage Smallpox and its Eradication (1988), il est indiqué que la variole du singe est une maladie systémique grave accompagnée d’une éruption pustuleuse généralisée et qu’elle est cliniquement impossible à distinguer de la variole.
Outre les “virus” de la variole et de la variole du singe, 7 autres espèces de “poxvirus”, appartenant à 4 genres, peuvent provoquer des lésions chez l’homme.
La variole du singe a posé un problème de diagnostic potentiel lors de l’éradication mondiale de la variole, car les particules de “virus” trouvées dans les lésions par examen au microscope électronique pouvaient être confondues avec celles du “virus” de la variole.
En d’autres termes, on a trouvé exactement les mêmes particules non purifiées/non isolées dans les cultures, mais on a prétendu qu’il s’agissait de “virus” différents.
Il était évident que si un réservoir animal du “virus” de la variole existait, l’éradication de la variole serait impossible (et voilà qu’un réservoir animal existe…).
Après la découverte de la variole du singe en 1958, l’OMS a enquêté sur d’autres épidémies.
Les enquêtes qui ont suivi ont révélé 4 autres épidémies signalées et 4 épidémies jusqu’alors non signalées chez les primates, mais aucun cas d’infection chez l’homme.
Dans l’un de ces cas, le “virus” de la variole du singe avait été récupéré dans des cultures de cellules normales de rein de cynomolgus.
Après la découverte de la variole du singe en Afrique en 1970, des sérums ont été collectés chez des singes et d’autres animaux au Zaïre et dans plusieurs pays d’Afrique occidentale.
Des “anticorps spécifiques du virus de la variole du singe” ont été mis en évidence dans les sérums de 8 espèces de singes et de 2 espèces d’écureuils (ce qui va à l’encontre des informations plus récentes de l’OMS selon lesquelles il n’existe pas d’anticorps spécifiques pour la variole du singe)
Bien que des primates d’Asie, d’Afrique et d’Amérique du Sud (et un fourmilier de cette dernière région) aient été infectés par le “virus” de la variole du singe en captivité, rien ne prouve que ce “virus” soit présent naturellement ailleurs qu’en Afrique.
Au cours de la période 1958-1968, un grand nombre de primates ont été importés d’Asie en Europe et en Amérique du Nord, et un plus petit nombre d’Afrique occidentale, principalement pour la fabrication et les tests de sécurité des vaccins contre la poliomyélite.
En d’autres termes, les animaux utilisés pour les tests des vaccins expérimentaux sont tombés malades entre les expériences, pendant le transport dans des conditions horribles
Il a été signalé que des variants appelés “virus de la variole”, qui ressemblaient au “virus” de la variole par tous les tests biologiques, pouvaient être récupérés à partir de certains stocks de laboratoire du “virus” de la variole du singe, soit par passage dans des hamsters, soit par inoculation sur la membrane chorio-allantoïque.
Cette découverte a soulevé d’importantes questions quant à la possibilité d’un réservoir animal du “virus” de la variole, mais ces questions ont été écartées par la suite (rappelez-vous qu’ils ont admis que la variole ne pourrait pas être éradiquée si un réservoir animal était découvert).
Vers 1982, l’accumulation des preuves a convaincu la plupart des laborantins que les “virus de la variole” étaient en fait des souches du “virus” de la variole introduites par inadvertance comme contaminants de laboratoire (comme c’est pratique…).
L'”isolement” de “virus” à partir d’animaux capturés sur le terrain est probablement un événement rare dans les infections à “orthopoxvirus”, dans lesquelles une infection persistante ne se produit pas, et en fait, un seul “isolement” de ce type a été effectué.
La dernière épidémie connue de variole dans la zone de Basankusu s’est produite en 1968 et a comporté 70 cas dont 18 décès.
Plusieurs cas suspects de variole ont été traités à l’hôpital en 1969, mais aucun n’a été confirmé.
Deux cas suspects ont été signalés en 1970 ; l’un d’entre eux s’est avéré être la varicelle, et l’autre a été le premier cas de monkeypox humain à être détecté.
Le premier cas de variole du singe présentait, le 9e jour, une éruption cutanée dont la distribution centrifuge était caractéristique de la variole.
Le patient s’est rétabli et était sur le point de sortir, mais le 23 octobre, il a développé une rougeole (contractée pendant son séjour à l’hôpital) et est décédé 6 jours plus tard (la rougeole était aussi régulièrement confondue avec la variole).
La découverte de cas de variole humaine en Afrique centrale en septembre 1970 a été suivie de la démonstration que 4 cas de variole suspectés au Liberia et 1 cas en Sierra Leone en 1970, et 1 cas au Nigeria et en Côte d’Ivoire en 1971 étaient tous des cas de monkeypox humaine (on ne peut pas avoir des cas de variole qui apparaissent alors qu’elle est “éradiquée…”).
Les virologues qui s’intéressent aux “poxvirus” savaient depuis 1959 que le “virus” de la variole du singe pouvait provoquer une maladie généralisée ressemblant à la variole chez les singes cynomolgus, et dans les années 1960, des cas similaires ont été reconnus chez d’autres espèces de singes et chez les singes anthropoïdes.
Lors de la première réunion du Groupe informel de l’OMS sur la variole du singe et les virus apparentés, qui s’est tenue à Moscou en mars 1969, les experts ont convenu que la première indication que le “virus” récupéré d’une lésion cutanée pourrait être le “virus” de la variole du singe serait l’aspect hémorragique des boutons produits sur la membrane chorioallantoïque après 3 jours d’incubation à 35° C.
Le 23 septembre 1970, les docteurs S. S. Marennikova, E. M. Shelukhina et N. N. Maltseva, du centre collaborateur de l’OMS à Moscou, ont récupéré un “virus” sur la membrane chorio-allantoïque à partir de matériel envoyé par un patient au Zaïre.
Après une incubation de deux jours, les taches étaient “parfaitement typiques” du “virus” de la variole.
Cependant, après un autre jour d’incubation à 35°C, une hémorragie a été observée autour des pustules, une caractéristique jamais observée avec le “virus” variolique et caractéristique du “virus” de la variole du singe.
En d’autres termes, ils ont déterminé que l’apparition hémorragique de la membrane chorioallantoïque après un jour supplémentaire d’incubation était la variole du singe.
Entre-temps, un diagnostic de “virus” de la variole a été établi au centre de collaboration de l’OMS à Atlanta à partir de matériel provenant de deux cas de maladie ressemblant à la variole découverts dans différentes régions du Liberia à la mi-septembre.
Ce diagnostic a suscité une grande inquiétude, car on pensait que le Liberia était exempt de variole depuis 1969.
Ils ont décidé que les isolats devaient être soigneusement examinés au moyen de tests appropriés afin de déterminer s’il pouvait s’agir du “virus” de la variole du singe.
Les isolats libériens, ainsi que les isolats ultérieurs de la Sierra Leone et du Nigeria, se sont avérés avoir les caractéristiques du “virus” de la variole du singe (la magie de la virologie…).
Des dispositions ont été prises pour un examen plus approfondi des isolats du Zaïre et du Libéria et les travaux sur ces isolats ont constitué le principal sujet de discussion lors de la deuxième réunion du Groupe informel sur la variole du singe et les virus apparentés en février 1971.
Les “experts” présents à cette réunion ont convenu que ces isolats étaient bien des “virus” de la variole du singe.
Cette conclusion a été une source de soulagement considérable, car elle excluait la possibilité que la variole se soit reproduite dans les situations épidémiologiques les plus improbables (whew…)
Cliniquement, la variole humaine ressemble beaucoup à une variole discrète de type ordinaire ou, parfois, de type modifié.
La caractéristique clinique évidente qui différencie la variole du singe de la variole est l’élargissement prononcé des ganglions lymphatiques observé dans la plupart des cas de variole du singe (mais pas dans tous).
L’hypertrophie des ganglions lymphatiques a été observée dans 90 % des 98 cas dans lesquels sa présence ou son absence a été enregistrée et était un signe présent, précédant l’éruption, dans 65 % de ces cas.
L’éruption commence après une maladie prodromique qui dure 1-3 jours, avec de la fièvre, une prostration et généralement une hypertrophie des ganglions lymphatiques.
Comme dans le cas de la variole, les lésions se développent plus ou moins simultanément et évoluent à la même vitesse, à travers des papules, des vésicules et des pustules, avant de s’ombiliquer, de sécher et de desquamer.
Comme dans le cas de la variole, des cicatrices en forme de piqûres peuvent se développer, le plus souvent sur le visage, mais elles ont tendance à diminuer en importance avec le temps.
Tout au long des enquêtes, une grande importance a été accordée à la confirmation en laboratoire des diagnostics clinico-épidémiologiques, d’abord en raison de la présence possible de la variole, puis de la suspicion d’une infection humaine par le “virus de la variole blanche”.
Les méthodes de diagnostic de laboratoire étaient les mêmes que celles utilisées pour la variole, complétées par une sérologie (non spécifique) dans les cas où l’isolement “viral” n’était pas possible.
Cette combinaison a permis de poser des diagnostics positifs dans la grande majorité des cas (qu’en est-il de ceux où le diagnostic n’a pu être posé… ?)
Pratiquement tous les cas trouvés positifs par microscopie électronique l’étaient aussi par culture, et vice versa (pourquoi ne serait-ce pas le cas puisque le matériel de microscopie électronique provient de la culture… ?) mais 60 (22%) des cas ont été vus trop tard pour obtenir du matériel lésionnel et n’ont pu être confirmés que par sérologie (qui, encore une fois, n’est pas spécifique en raison des réactions croisées avec la variole et d’autres “virus”).
L’OMS a entrepris des tests sérologiques à partir de quelque 200 sérums provenant de zones éloignées de ce qui est maintenant reconnu comme la zone d’enzootie de la variole du singe et tous étaient pratiquement négatifs, alors que les sérums de singes du Zaïre prélevés en 1971 et 1973 se sont révélés 14 sur 81 positifs par le test HI et 11 sur 65 par le test de neutralisation
Par la suite, une autre collecte de sérums au Zaïre a donné 24 sérums de singe HI-positifs sur 117 testés et 26 sérums de rongeur HI-positifs sur 245 testés.
Des tentatives ont été faites pour isoler le “virus” sur la membrane chorio-allantoïque des reins de primates, de rats et d’écureuils collectés au Zaïre.
Aucun n’a donné de “virus” de la variole du singe, mais le “virus” de la variole blanche aurait été obtenu à partir de 4 spécimens et le “virus” de la vaccine à partir d’un spécimen.
Dans une autre étude sérologique de l’OMS, 1331 sérums provenant de 45 espèces d’animaux sauvages ont été testés par le test HI comme test de dépistage des anticorps contre les “orthopoxvirus” ; 227 sérums (17%), provenant d’un large éventail d’animaux, ont donné des résultats positifs.
Les 50 sérums provenant de Rattus spp. étaient tous négatifs.
L’analyse ultérieure de certains sérums par des tests d’adsorption radio-immunologique a jeté un doute sur la signification des résultats positifs obtenus par le test IH, puisque aucun des 25 sérums IH-positifs de l’écureuil Heliosciurus rufobrachium n’a donné de résultats positifs par radio-immunologie.
Les reins et les rates de 930 animaux de l’étude de 1979 sur le Zaïre, y compris tous les singes, ont été mis en culture dans des cellules Vero, et le matériel de singe a également été testé sur la membrane chorio-allantoïque, avec des résultats négatifs.
Ce que tout cela signifie, c’est que les résultats des anticorps ne veulent absolument rien dire.
Le chapitre conclut que la variole du singe s’est avérée en 1970 être l’agent causal d’une infection humaine généralisée qui ressemblait cliniquement à la variole.
On a prétendu que la lymphadénopathie était une caractéristique essentielle de la variole du singe, mais elle n’est pas toujours présente.
Le plus souvent, la maladie commence par des symptômes non spécifiques, semblables à ceux de la grippe.
La pathologie des ganglions lymphatiques dans les cas de variole naturelle est mal décrite.
Councilman et al. (1904) notent que dans la littérature antérieure au 20e siècle, “très peu d’attention a été accordée à l’état des ganglions lymphatiques dans la variole”.
Dans sa série de cas, Bras (1952) rapporte que les ganglions lymphatiques n’étaient pas examinés régulièrement et que leur description se limite à trois phrases.
Parmi les données disponibles, les modifications ganglionnaires brutes les plus fréquemment rapportées sont l’hypertrophie et l’hyperémie
Histologiquement, l’hypertrophie, si elle est présente, semble être due principalement à l’œdème et à la congestion.
Councilman a spécifiquement déclaré que “l’élargissement du ganglion est davantage dû à l’œdème qu’à l’hyperplasie cellulaire”.
Avant l’éradication de la variole, les infections humaines à MPXV étaient probablement diagnostiquées à tort comme des infections à VARV en raison de la prévalence de la variole et de la similitude de la présentation et de l’évolution de la maladie cutanée.
La variole du singe n’a pas été reconnue comme une maladie distincte de la variole jusqu’en 1970, lorsque l’élimination de la variole en République démocratique du Congo a révélé la persistance d’une maladie semblable à la variole.
La lymphadénopathie et le gonflement des ganglions lymphatiques sont des réactions connues à la vaccination antivariolique.
La lymphandénite postvaccinale est l’expression désignant les changements réactifs qui se produisent dans les ganglions lymphatiques en réponse à une vaccination antivariolique.
Les réactions indésirables signalées lors de la vaccination antivariolique dans les années 1980 comprenaient une lymphadénopathie, de la fièvre ou des frissons et une sensibilité au niveau du site de vaccination.
La variole ou… ?
La variole a-t-elle réellement été éradiquée comme le prétendait l’OMS en 1980 ? Cela dépend de la définition du terme “éradiquer”. Si l’on se réfère à l’élimination du nom “variole” utilisé pour décrire un ensemble de symptômes reconnaissables de la maladie, alors la réponse est un OUI absolu puisque le nom a été retiré et remplacé par celui de variole du singe (ou de varicelle, de rougeole, de rubéole, etc.). Si l’on se réfère à la suppression complète des symptômes associés au nom, alors la réponse est un NON catégorique, car les mêmes symptômes de la maladie apparaissent dans diverses maladies sous des noms différents et sont même acquis par des vaccinations de routine. L'”éradication” de la variole n’était rien de plus qu’un écran de fumée utilisé pour vendre au monde le “miracle” de la vaccination. C’est une affirmation qui ne résiste pas à un examen approfondi.
Source (anglais) : https://viroliegy.com/2022/01/05/was-smallpox-really-eradicated/
Plus de ressources : http://whale.to/vaccines/smallpox.html
Partout dans le monde, des personnes affirment que la pandémie est un mythe. C’est au Japon, en Suède, au Royaume-Uni et au Danemark que cette idée est la moins répandue, avec des résultats allant de trois à cinq pour cent. D’autre part, 30 % des personnes en Inde et 10% en France croient que “le coronavirus est un mythe produit par certaines forces puissantes et que le virus n’existe pas vraiment”.
Où les gens croient que le covid est un mythe
% disant que ce qui suit est vrai : “le coronavirus est un mythe créé par certaines forces puissantes et le virus n’existe pas vraiment”.
C’est la question utilisée lors d’un récent sondage YouGov visant à déterminer dans quelle mesure les gens du monde entier pensent ainsi.
En Inde, où 30 % des participants (urbains) partageaient cette opinion sur l’épidémie, la croyance en cette idée était de loin la plus populaire des 24 nations interrogées.
Les scientifiques et les médecins ont déjà réalisé d’innombrables expériences pour tenter de prouver la théorie des germes au cours des 120 dernières années, et toutes ont échoué. Voici quelques-unes des expériences qui ont été réalisées sur le rhume, la grippe et la rougeole.
En mars 1919, Rosenau et Keegan ont mené 9 expériences distinctes sur un groupe de 49 hommes en bonne santé, afin de prouver la contagion. Dans les 9 expériences, 0/49 hommes sont tombés malades après avoir été exposés à des personnes malades ou aux fluides corporels de personnes malades. En novembre 1919, Rosenau et al. ont mené 8 expériences distinctes sur un groupe de 62 hommes pour tenter de prouver que le virus de la grippe est contagieux et provoque la maladie. Dans les 8 expériences, 0/62 hommes sont tombés malades. Une autre série de 8 expériences a été entreprise en décembre 1919 par McCoy et al. sur 50 hommes pour essayer de prouver la contagion. Une fois encore, les 8 expériences n’ont pas réussi à prouver que les personnes atteintes de la grippe ou leurs fluides corporels provoquaient la maladie. 0/50 hommes sont tombés malades.
En 1919, Wahl et al. ont mené 3 expériences distinctes pour infecter 6 hommes sains avec la grippe en les exposant à des sécrétions des muqueuses et des tissus pulmonaires de personnes malades. 0/6 hommes ont contracté la grippe dans chacune des trois études.
En 1920, Schmidt et al ont mené deux expériences comparatives, exposant des personnes en bonne santé aux fluides corporels de personnes malades. Sur 196 personnes exposées aux sécrétions des muqueuses de personnes malades, 21 (10,7 %) ont développé un rhume et trois ont développé une grippe (1,5 %). Dans le second groupe, sur les 84 personnes saines exposées aux sécrétions des muqueuses de personnes malades, cinq ont développé la grippe (5,9 %) et quatre des rhumes (4,7 %). Sur quarante-trois témoins qui avaient été inoculés avec des solutions salines physiologiques stériles, huit (18,6 %) ont développé des rhumes. Un pourcentage plus élevé de personnes ont été malades après avoir été exposées à la solution saline par rapport à celles qui ont été exposées au “virus”.
En 1921, Williams et al. ont essayé d’infecter expérimentalement 45 hommes sains avec le rhume et la grippe, en les exposant à des sécrétions des muqueuses de personnes malades. 0/45 sont tombés malades.
En 1924, Robertson & Groves ont exposé 100 personnes en bonne santé aux sécrétions corporelles de 16 personnes différentes souffrant de la grippe. Les auteurs ont conclu qu’aucune personne sur 100 n’était tombée malade à la suite de cette exposition aux sécrétions corporelles.
En 1930, Dochez et al. ont tenté d’infecter expérimentalement un groupe d’hommes avec le rhume. Les auteurs ont déclaré quelque chose d’étonnant dans leurs résultats.
“Il est apparu très tôt que cet individu était peu fiable et, dès le début, il a été possible de le tenir dans l’ignorance de notre procédure. Il présentait des symptômes discrets après son injection-test de bouillon stérile et pas de résultats plus frappants avec le filtrat froid, jusqu’à ce qu’un assistant, le deuxième jour après l’injection, fasse par inadvertance référence à cet échec à contracter un rhume.
Ce soir-là et cette nuit-là, le sujet a fait état d’une symptomatologie sévère, comprenant des éternuements, une toux, un mal de gorge et une congestion nasale. Le lendemain matin, il a appris qu’il avait été mal informé sur la nature du filtrat et ses symptômes ont disparu dans l’heure qui a suivi. Il est important de noter qu’il y avait une absence totale de changements pathologiques objectifs.”
En 1940, Burnet et Foley ont essayé d’infecter expérimentalement 15 étudiants universitaires avec la grippe. Les auteurs ont conclu que leur expérience était un échec.
Voici 4 autres expériences menées en 1918 pour prouver la contagion mais qui ont échoué.
“Notre analyse n’a trouvé aucune étude expérimentale humaine publiée dans la littérature anglophone décrivant clairement la transmission de la grippe de personne à personne.
Aucune preuve de la transmission de la rougeole
Voici les études réalisées à ce jour pour tenter de prouver que la rougeole est contagieuse, toutes n’ayant pas apporté de preuves concluantes :
En 1799, le Dr Green a rapporté qu’il avait réussi à infecter trois enfants en les exposant au fluide de lésions de rougeole, mais il n’existe aucun document fiable à ce sujet(1).
En 1809, Willan a essayé d’infecter trois enfants en les exposant au fluide de lésions de rougeole provenant de personnes malades. Aucun des enfants n’est tombé malade(1).
En 1810, Waschel a prétendu avoir infecté expérimentalement un homme de 18 ans avec la rougeole, mais ces affirmations ont été contestées par d’autres personnes à l’époque. L’homme est tombé malade 22 jours après l’inoculation et il est dit que l’homme a en fait contracté la rougeole naturellement et non à cause de l’inoculation(1).
En 1822, le Dr Frigori a essayé de contaminer 6 enfants avec la rougeole. Bien que les enfants aient développé des symptômes légers et non spécifiques, ils n’ont pas développé la rougeole. Mécontent de ses résultats, Frigori a tenté de s’infecter lui-même, mais sans succès(1).
En 1822, le Dr Negri a essayé d’infecter deux enfants avec la rougeole, mais il a eu les mêmes résultats négatifs que le Dr Frigori.(1)
En 1822, Speranza a essayé d’infecter 4 enfants en utilisant des méthodes similaires, mais sans succès(1)
En 1834, Albers a essayé de contaminer quatre enfants avec la rougeole, mais aucun n’est tombé malade(1).
Entre 1845 et 1851, Mayr aurait réussi à infecter 6 enfants avec la rougeole, mais il semble s’agir d’une forme modifiée de la maladie (en d’autres termes, pas la rougeole)(1).
En 1890, Hugh Thompson a essayé d’infecter des enfants avec la rougeole à deux reprises, mais les deux tentatives ont échoué(1).
En 1905, Ludvig Hektoen rapporte qu’il a réussi à infecter deux personnes saines avec le sang de patients atteints de la rougeole(1). Il convient de noter que le sang était mélangé à d’autres substances, comme le liquide d’ascite, avant d’être injecté. Cette expérience est considérée comme la meilleure preuve qui prouve sans aucun doute que le virus de la rougeole provoque la maladie(2). Il existe peu de détails spécifiques sur les signes et les symptômes que ces patients ont réellement présentés, de sorte que l’on peut douter qu’ils aient réellement eu la rougeole(3).
En 1915, Charles Herman a frotté la muqueuse nasale de 40 nourrissons avec des cotons-tiges recouverts de sécrétions nasales de patients atteints de la rougeole. La majorité des nourrissons n’ont eu aucune réaction, 15 nourrissons ont eu une légère augmentation de la température corporelle et quelques-uns ont développé des taches rouges sur la peau. À l’âge de 1 an, 4 de ces nourrissons ont eu des contacts rapprochés avec des personnes infectées. Aucun des nourrissons n’est tombé malade, ce qui serait dû à leur “immunité”(4).
En 1919, Sellards a essayé d’inoculer 8 hommes en bonne santé (n’ayant pas été exposés à la rougeole auparavant). En 1919, Sellards a essayé d’inoculer 8 hommes en bonne santé (sans exposition préalable à la rougeole) avec le sang de malades de la rougeole, en utilisant les mêmes méthodes que Hektoen. Aucun des hommes n’est tombé malade(3,5). Quelques semaines plus tard, les volontaires ont été exposés à un cas de rougeole, mais aucun d’entre eux n’est tombé malade. Des sécrétions nasales ont alors été prélevées sur des patients atteints de la rougeole et injectées dans les voies nasales des participants sains. Aucun n’est tombé malade(3,5).
Sellards a également mené une autre expérience pour essayer de contaminer deux autres volontaires humains sains avec la rougeole en leur injectant par voie sous-cutanée et intramusculaire le sang de deux patients infectés. Aucun des deux hommes n’est tombé malade(3,5).
En 1919, Alfred Hess fait un commentaire sur les résultats de Sellard. Il déclare : “Il est remarquable que Sellards ait été incapable de produire cette maladie hautement infectieuse au moyen du sang ou des sécrétions nasales d’individus infectés, il n’y a pas longtemps, j’ai été confronté à une expérience similaire avec la varicelle, nous sommes donc confrontés à deux maladies, les deux plus infectieuses des maladies endémiques dans cette partie du monde, que nous sommes incapables de transmettre artificiellement d’homme à homme”(6).
En 1924, Harry Bauguess a écrit un article dans lequel il déclarait : “Une recherche minutieuse dans la littérature ne révèle aucun cas où le sang d’un patient atteint de rougeole a été injecté dans le flux sanguin d’une autre personne et a produit la rougeole(7)”.
1. Hektoen L. Experimental Measles. J Infect Dis. 1905;2(2):238–255. doi:10.1093/infdis/2.2.238
2. Degkwitz R. The Etiology of Measles. J Infect Dis. 1927;41(4):304–316. doi:10.1093/infdis/41.4.304
3. SELLARDS AW. A REVIEW OF THE INVESTIGATIONS CONCERNING THE ETIOLOGY OF MEASLES. Medicine (Baltimore). 1924;3(2):99–136. doi:10.1097/00005792–192403020–00001
4. Herman C. Immunization against measles. Arch Pediat. 1915;32(503). [mentionné ici]
5. Sellards A. Insusceptibility of man to inoculation with blood from measles patients. Bull Johns Hopkins Hosp. 1919;257. [mentionné ici]
6. Hess AF. NEED OF FURTHER RESEARCH ON THE TRANSMISSIBILITY OF MEASLES AND VARICELLA. J Am Med Assoc. 1919;73(16):1232. doi:10.1001/jama.1919.0261042006002
En 2018, une revue sur les différentes voies de transmission des “virus” respiratoires a été publiée par Kutter et al. Les chercheurs passent en revue de nombreux “virus” différents et tentent d’identifier les différents modes de transmission pour chacun d’entre eux, mais il devient très clair que les preuves sont soit extrêmement faibles, soit totalement inexistantes. Par exemple, ils affirment que :
• La plupart des études sur les voies de transmission interhumaines ne sont pas concluantes.
• L’importance relative des voies de transmission des virus respiratoires n’est pas connue.
De nombreuses épidémies ont fait l’objet d’une enquête rétrospective afin d’étudier les voies possibles de transmission des virus interhumains. Les résultats de ces études sont souvent peu concluants et, parallèlement, les données issues d’expériences comparatives sont rares. Par conséquent, les connaissances fondamentales sur les voies de transmission qui pourraient être utilisées pour améliorer les stratégies de prévention font toujours défaut.
TERRAIN expose la tyrannie de la fausse pandémie mondiale, fondée sur le modèle erroné de la maladie connu sous le nom de “théorie des germes”. Ce documentaire en deux parties explore la théorie du terrain, un modèle de santé qui fonctionne en symbiose avec la nature pour promouvoir le bien-être et la guérison, sans recourir à un paradigme médical corrompu et défectueux.
TERRAIN motive et inspire les spectateurs à comprendre le pouvoir et la responsabilité du consentement.
La première partie de TERRAIN remet en question la théorie des germes, un système de croyance obsolète et non scientifique basé sur des fraudes et des mauvaises interprétations.
La deuxième partie de TERRAIN explore les conséquences globales de l’adoption d’un modèle de santé non viable basé sur la théorie des germes et ouvre la porte à un biome synergique d’autocorrection et de guérison connu par tous les êtres vivants sous le nom de théorie du terrain.
Un film produit par Marcelina Cravat et Andrew Kaufman.
Avec le Dr Andrew Kaufman, le Dr Barre Lando, le Dr Stefan Lanka, le Dr Mark McDonald, le Dr Tom Cowan, le Dr Kelly Brogan, le Dr Samantha Bailey, Sayer Ji, Sally Fallon, Peggy Hall, Tony Roman, Alphonso Faggiolo et Veda Austin.
Un mathématicien allemand travaillant avec le Dr Stefan Lanka vient de publier un rapport intitulé “Analyse structurelle des données de séquençage en virologie – Une approche élémentaire à l’aide de l’exemple du SARS-CoV-2FR“. Il fournit encore plus de preuves que les virologues sont pris dans un monde de simulations informatiques – des simulations qui ne sont pas fiables même selon leurs propres termes, sans compter qu’elles sont déconnectées de la réalité. Cette analyse est une contribution importante qui expose un autre élément de l’anti-science utilisée pour soutenir cette fausse pandémie. En outre, il s’agit d’un démantèlement technique de la manière dont tous les “virus” sont inventés et ensuite “trouvés”, dans un jeu de tromperie permanent.
L’article est très technique et nécessite une certaine compréhension de la manière dont les virologues créent un “génome”, en partant d’un échantillon brut provenant d’un patient prétendument infecté par le virus “COVID-19”. Pour vous faciliter la tâche, j’ai produit un résumé des principales conclusions, présentées ci-dessous :
Il a été démontré qu’aucune des séquences génétiques utilisées pour produire les génomes du ” SARS-CoV-2 ” ne provenait de l’intérieur d’un virus. L’origine des fragments génétiques n’est pas claire.
La séquence originale de novo du ” SARS-CoV-2 ” construite par ordinateur et publiée par Fan Wu et al n’a pas pu être reproduite par la méthodologie décrite dans leur article, ce qui soulève des questions sur la façon dont ils l’ont produite et ont annoncé le nouveau ” virus ” au monde.
Les protocoles PCR sont calibrés sur des séquences d’origine non confirmée que l’on retrouve clairement chez de nombreux humains et apparemment aussi chez d’autres choses. Il n’a pas été démontré que le processus PCR permettait de détecter un “virus”, et encore moins de diagnostiquer une maladie inventée appelée “COVID-19”.
Les virologues se trompent eux-mêmes en effectuant des amplifications à 35 ou 45 cycles, car cela peut entraîner la “détection” de séquences qui ne sont même pas présentes dans l’échantillon. En effet, la méthodologie peut aboutir à la “détection” de n’importe quelle séquence qu’ils espèrent trouver.
Fan Wu et al auraient pu trouver de meilleures correspondances pour le “VIH” et le “virus de l’hépatite D” que pour “un nouveau coronavirus” chez leur homme de 41 ans de Wuhan, qui a présenté une pneumonie comme l’un des premiers cas déclarés de “COVID-19”. S’ils veulent trouver un “virus”, tout dépend de ce qu’ils demandent à l’ordinateur de chercher.
Bien sûr, cela a beaucoup plus de sens quand on s’attaque à la racine du problème : le ” SARS-CoV-2 ” n’est rien de plus qu’une simulation informatique et il n’y a jamais eu de virus à l’origine – tout cela est une fraude mondialeFR. La virologie semble ignorer qu’elle s’enfonce davantage dans une crise épistémologique, et pas seulement dans le domaine de la génomique, comme le souligne cet article de Mike Stone. Dans l’article de Stone, j’ai remarqué dans la section des commentaires que le Dr Valendar Turner du Perth Group a souligné que feu Sir John Maddox, ancien rédacteur en chef de Nature, avait lancé un avertissement pertinent en 1988. Il semble que ceux qui s’immergent dans le monde des techniques de détection moléculaire indirecte risquent de ne plus voir la forêt derrière les arbres, comme il le déclarait si justement :
“N’y a-t-il pas un danger, en biologie moléculaire, que l’accumulation de données prenne tellement d’avance sur leur assimilation dans un cadre conceptuel que les données finissent par constituer un obstacle ? Le problème vient en partie du fait que l’excitation de la chasse laisse peu de temps à la réflexion. Il y a des subventions pour produire des données, mais pratiquement aucune pour prendre du recul et réfléchir.”
Maddox, J. Nature 335, 11 (1998)
Nous nous efforcerons de continuer à dénoncerFR ces méthodologies antiscientifiques et d’encourager les autres à se demander si l’industrie de la virologie, qui représente des milliards de dollars, et les “traitements” bidon qui y sont associés et qui proviennent du gigantesque complexe pharmaceutique, aident réellement les gens à améliorer leur santé. Pour ceux d’entre nous qui voient qu’il n’y a aucune base solide à tout cela, il n’y a aucune chance que nous suivions les conseils des médecins et des scientifiques qui font la promotion de ces modèles malsains. Et, ce qui est peut-être encore plus important, nous savons qu’il ne faut prendre aucun des produits pharmaceutiques frauduleux et de plus en plus pervers qui sont le produit de cette pseudo-science et qui sont utilisés comme véhicules pour délivrer des composants néfastes et non répertoriés. Une fois de plus, vous pouvez éviter tous ces problèmes en indiquant :
Où est le virus* ?
*Particule minuscule qui est un parasite intracellulaire obligatoire (c’est-à-dire capable de se répliquer et transmissible) contenant un génome entouré d’une enveloppe protéique protectrice, codée par le virus.
Auteur : Dr. Mark Bailey
Mark est un chercheur dans le domaine de la microbiologie, de l’industrie médicale et de la santé qui a travaillé dans la pratique médicale, y compris les essais cliniques, pendant deux décennies.
La question de l’existence de virus pathogènes reste importante, car la croyance en de tels virus mobilise des milliards de dollars de ressources et de fonds de recherche. Ces deux dernières années, nous avons également vu comment un prétendu virus peut être utilisé comme un outil politique pour mettre les populations au pas. Ce n’est pas la première fois que cela se produit : par exemple, la “découverte” du VIH dans les années 1980 a donné naissance à une industrie de plusieurs milliards de dollars et a également été utilisée à des fins politiques dans la plupart des régions du monde. (Les erreurs concernant l’existence de la particule du VIH et le fait qu’elle soit à l’origine du sida sont décrites dans Virus ManiaFR. Pour ceux qui souhaitent approfondir le sujet, je recommande le magnus opus de The Perth Group sur ce sujet).
“Les virus sont de petits parasites intracellulaires obligatoires qui, par définition, contiennent un génome d’ARN ou d’ADN entouré d’une enveloppe protéique protectrice, codée par le virus.”
Medical Microbiology, 4th edition, 1996
Le journaliste indépendant Jeremy Hammond, qui se présente comme exposant la “dangereuse propagande d’Etat” entourant le COVID-19 et les dangers des vaccins, a ainsi fait la curieuse déclaration suivante en 2021 :
“l’affirmation fausse selon laquelle le SARS-CoV-2 n’a jamais été isolé (c’est-à-dire que son existence n’a jamais été prouvée) nuit considérablement à la crédibilité du mouvement pour la liberté de la santé et repose sur une ignorance totale de la science (le virus est constamment isolé et son génome entier est séquencé par des scientifiques du monde entier)”.
Jeremy Hammond, 9 mars 2021
Je dirais que l’ignorance est du côté de Hammond, qui semble parvenir à sa conclusion en répétant essentiellement les affirmations des virologues et en rassurant le public sur la validité de leurs méthodologies. Ces dernières semaines, nous avons également vu le Dr Joseph Mercola présenter l’interview de Hammond et le blog de Steve Kirsch (qui fait également appel à l’autorité de la virologie) comme des “preuves” de l’existence du SARS-CoV-2. Kirsch déclare s’appuyer sur “les avis des experts en qui j’ai confiance”, ce qui signifie qu’il a remis l’argument entre les mains d’autres personnes plutôt que d’enquêter lui-même sur la question. Mais est-il sage pour ces combattants de la liberté sanitaire qui s’opposent aux “experts” de l’establishment COVID de ne pas également remettre en question les virologues de l’establishment ?
Le Dr Andy Kaufman a produit une réfutation point par point du soutien de Hammond à la méthodologie d'”isolement” de la virologie moderne ici, tandis que le Dr Tom Cowan a prévenu que nous ne faisions que commencer à démanteler les absurdités de la virologie ici. Le Dr Sam Bailey a publié de nombreuses vidéos sur la question de l’isolement des virus, dont la plupart ont été interdites sur YouTube mais peuvent encore être trouvées sur Odysee. En outre, dans un essai que j’ai cosigné avec le Dr John Bevan-Smith, nous décrivons le premier pilier de la fraude COVID-19FR comme l’utilisation abusive du terme “isolement” par la virologie. En résumé, comme les virologues n’ont pas été en mesure d’isoler physiquement le moindre virus au siècle dernier, ils ont simplement changé la définition du mot, de sorte que même les virologues admettent que le terme est désormais utilisé de manière vague. Une situation étrange lorsque la méthode scientifique exige une terminologie précise.
J’ai observé au cours des deux dernières années que de nombreux scientifiques, médecins et journalistes sont heureux de sauter par-dessus ce gouffre de l'”isolement” et de citer les “génomes de coronavirus” déposés dans des bases de données comme preuve que le virus doit exister. Par exemple, Steve Kirsch écrit dans son blog que :
“Je sais que Sabine Hazan a vérifié que la séquence du virus obtenue auprès de l’ATCC correspondait exactement à ce qu’elle a trouvé chez les personnes atteintes du virus.”
Steve Kirsch, 10 janvier 2022
Il cite l’article de Hazan “Detection of SARS-CoV-2 from patient fecal samples by whole genome sequencing” comme preuve de cette affirmation. Kirsch admet qu’il ne sait pas comment les génomes ont été créés, mais ses…
“amis scientifiques semblent satisfaits avec eux. À 2 000 $ la dose, je ne pense pas qu’ils commercialiseraient le produit s’il était contaminé et inutile. Ai-je tort ?”
Steve Kirsch, 10 janvier 2022
Malheureusement, il semble avoir été dupé par la façade high-tech du génie génomique de la virologie, où des “virus” sont créés à partir de diverses séquences génétiques détectées. En fait, il arrive que les séquences ne soient pas vraiment détectées du tout, comme l’expose le Dr Stefan Lanka dans ce qui pourrait être le coup de grâce de la virologieFR.
L’article de Hazan peut servir d’exemple de la méthodologie défectueuse utilisée pour créer ces “génomes de virus”. L’équipe de recherche a obtenu des échantillons de matières fécales de 14 participants et a procédé à l’examen des séquences génétiques qu’elle pouvait détecter dans ces échantillons. Le premier problème se pose dans la section “méthodes”, lorsque l’équipe déclare que “le contrôle positif du SARS-CoV-2 de l’ATCC (SARS-CoV-2 inactivé par la chaleur, VR-1986HK ; souche 2019-nCoV/USA-WA1/2020) a été inclus tout au long du traitement de l’échantillon”. Comment ont-ils su que l’échantillon contenait le virus inactivé ? Parce que l’ATCC (American Type Culture Collection) l’affirme sur son site Web en déclarant que “cette souche a été isolée à l’origine d’un cas humain dans l’État de Washington et a été déposée par les Centers for Disease Control and Prevention”. Et comment les CDC ont-ils su qu’ils avaient le virus ? Parce qu’ils ont affirmé l’avoir trouvé dans cet article.
“Coronavirus 2 du syndrome respiratoire aigu sévère d’un patient atteint d’une maladie à coronavirus, États-Unis” Mais où était le virus ?
Dans le document des CDC, il est dit qu’ils ont recueilli “des spécimens cliniques d’un patient ayant contracté le COVID-19 lors d’un voyage en Chine et qui a été identifié à Washington, aux Etats-Unis”. Ils ont conclu que le patient avait le COVID-19 sur la base d’un résultat de PCR qui a détecté certaines séquences dites provenir du SARS-CoV-2. Mais à ce stade, ils n’avaient aucune preuve de l’existence d’un virus – tout ce qu’ils avaient, c’était quelques séquences génétiques détectées chez un patient atteint d’une infection virale présumée. Après avoir réalisé une expérience de culture tissulaire en tube à essai sur leur échantillon clinique et prétendu qu’il y avait des preuves de la présence d’un virus en raison d’effets cytopathiquesFR non spécifiques, ils ont commencé à construire leur “génome”. Ils déclarent que “nous avons utilisé 50 μL de lysat viral pour l’extraction de l’acide nucléique total pour les tests de confirmation et le séquençage.” Il s’agit d’un autre tour de passe-passe, car il n’a pas été démontré que le “lysat viral” provenait d’un virus, il s’agit simplement d’une soupe de cultures de cellules fragmentées et d’autres additifs.
L’affirmation selon laquelle ils ont “extrait l’acide nucléique des isolats” est tout aussi trompeuse. Ils ont laissé entendre qu’ils ont isolé un virus et qu’ils savent quelles séquences d’ARN proviennent de son contenu. Cependant, cela nécessiterait que les prétendues particules virales soient réellement isolées physiquement par purification, ce qu’ils n’ont pas fait. Et je dis “présumées” parce que même s’ils purifiaient les particules, il faudrait encore démontrer qu’elles répondent à la définition d’un virus – y compris le fait d’être un parasite et l’agent causal de la maladie – ce qui n’a pas été démontré par ces auteurs ni par aucun autreFR.
Dans tous les cas, comment ont-ils su quelles séquences génétiques appartenaient au “virus” en premier lieu ? Ils ont “conçu 37 paires de PCR emboîtées couvrant le génome sur la base de la séquence de référence du coronavirus (numéro d’accession GenBank NC045512)”. Et d’où vient cette “séquence de référence” ? Cela se rapporte à l’article de Fan Wu, et al décrivant l’homme de 41 ans qui a été admis à l’hôpital central de Wuhan le 26 décembre 2019 avec une pneumonie bilatérale et malgré l’absence de nouvelles caractéristiques cliniques, on a dit qu’il était atteint d’une maladie qui a ensuite été appelée “COVID-19”.
Le spécimen était constitué de lavages pulmonaires bruts, il contenait donc un mélange de cellules humaines et potentiellement toutes sortes d’autres micro-organismes et fragments génétiques. Ils ont simplement affirmé qu’il y avait un virus dans le mélange. À partir de cet échantillon mixte, ils ont généré à l’aveugle des dizaines de millions de séquences différentes, puis ont mis leur logiciel au travail pour voir comment ils pouvaient les assembler. Pour réaliser cet “ajustement”, le logiciel a recherché des “contigs”, c’est-à-dire des zones où différents fragments semblent avoir des séquences qui se chevauchent. Parmi les centaines de milliers de séquences hypothétiques générées de cette manière, ils ont constaté que la plus longue séquence “continue” que l’ordinateur a pu créer faisait environ 30 000 bases et ont conclu que cette création informatique devait être le génome du nouveau virus présumé.
Ils pensaient qu’il s’agissait du génome parce que leur séquence de 30 000 bases générée de manière hypothétique était similaire à 89,1 % à ” un isolat de coronavirus (CoV) de chauve-souris semblable au SRAS, le SL-CoVZC45 “. Le “génome” de l'”isolat” de CoV de chauve-souris a été généré en 2018 après que “19 paires d’amorces PCR dégénérées ont été conçues par alignement multiple des séquences SARS-CoV et SL-CoV de chauve-souris disponibles déposées dans GenBank, ciblant presque toute la longueur du génome.” En d’autres termes, ils connaissaient déjà la séquence à rechercher sur la base des séquences qui avaient été précédemment déposées dans la GenBank. Mais comment les producteurs de ces séquences déjà déposées savaient-ils qu’ils avaient trouvé des génomes viraux ? Bienvenue dans le raisonnement circulaire de la virologie moderne.
Pour expliquer la boucle dans laquelle les virologues semblent être pris au piège, cet article de 2019 publié dans Virology illustre bien le problème :
“Trois méthodes principales basées sur le HTS [séquençage à haut débit] sont actuellement utilisées pour le séquençage du génome entier viral : le séquençage métagénomique, le séquençage par enrichissement de cible et le séquençage par amplicon PCR, chacune présentant des avantages et des inconvénients (Houldcroft et al., 2017). Dans le séquençage métagénomique, l’ADN (et/ou l’ARN) total d’un échantillon comprenant l’hôte mais aussi des bactéries, des virus et des champignons est extrait et séquencé. C’est une approche simple et rentable, et c’est la seule approche qui ne nécessite pas de séquences de référence. Au contraire, les deux autres approches HTS, l’enrichissement des cibles et le séquençage des amplicons, dépendent toutes deux d’informations de référence pour concevoir les appâts ou les amorces.”
Maurier F, et al, “A complete protocol for whole-genome sequencing of virus from clinical samples,” Virology, May 2019.
On touche là à la racine du problème. Les génomes de référence “viraux” sont créés par séquençage métagénomique, mais celui-ci est effectué sur des spécimens bruts (tels que des lavages de poumons ou des cultures de tissus non purifiés) et l’on déclare ensuite que les séquences sélectionnées sont d’origine virale. Il y a donc déjà deux problèmes : premièrement, il n’y a pas eu d’étape (c’est-à-dire de purification) pour montrer que les séquences proviennent de l’intérieur de “virus” et deuxièmement, comme décrit ci-dessus, les “génomes” générés par ordinateur sont simplement des modèles hypothétiques assemblés à partir de petits fragments génétiques, et non quelque chose dont l’existence a été prouvée dans la nature comme une séquence entière de 30 000 bases. Cependant, ces modèles in silico deviennent alors effectivement le “virus” et une entité telle que le SARS-CoV-2 est créée. Une fois que la première séquence de ce type est déposée dans une base de données, le “virus” peut être “trouvé” par d’autres grâce aux mêmes techniques métagénomiques défectueuses. Ou, comme l’indique l’article de Virology, il peut être “trouvé” par enrichissement de la cible et séquençage de l’amplicon (généralement par PCR), mais cela nécessite de disposer d’une séquence de référence… c’est-à-dire d’un modèle inventé in silico par séquençage métagénomique où la provenance des fragments génétiques était inconnue.
Il n’y a aucune partie dans le processus ci-dessus qui établit soit :
1) la composition génétique de toute particule imagée ou imaginée ; ou
2) la nature biologique de ces particules, c’est-à-dire ce qu’elles font réellement.
C’est une belle nanoparticule, mais de quoi est-elle faite et que fait-elle ?
Pouvons-nous maintenant revenir à l’article de Hazan pour constater qu’il s’agit d’un exercice inutile de virologie absurde. Ils déclarent qu’avec leur “contrôle positif du SARS-CoV-2 provenant de l’ATCC”, les “génomes des patients ont été comparés au génome de référence du SARS-CoV-2 Wuhan-Hu-1 (MN90847.3)”. Le numéro d’accès MN90847.3 fait référence au “génome” actualisé qui aurait été trouvé chez l’homme de 41 ans de Wuhan, comme indiqué ci-dessus dans l’article de Fan Wu et al. La boucle est bouclée : à aucun moment il n’a été démontré qu’il y avait un virus en suivant cette piste de “génomes”. L’équipe de Fan Wu n’a jamais trouvé de virus, elle a simplement affirmé que sa simulation informatique de séquence génétique était une “nouvelle souche de virus à ARN de la famille des Coronaviridae”, sans prouver que la séquence existait dans la nature ou provenait de l’intérieur d’un virus. Par conséquent, il n’y a pas eu de “détection du SARS-CoV-2 à partir d’échantillons de matières fécales de patients” comme le prétend le titre de l’article de Hazan, à moins que “SARS-CoV-2” ne signifie des séquences génétiques d’on-ne-sait-quoi provenant d’on-ne-sait-où. Peu importe où ou à quelle fréquence ces séquences sont détectées – il n’a jamais été prouvé qu’elles étaient de nature virale. Ainsi, lorsque Steve Kirsch affirme que Hazan “a vérifié que la séquence du virus obtenue de l’ATCC correspondait exactement à ce qu’elle a trouvé chez les personnes atteintes du virus”, il se trompe.
De quel “virus” parle-t-il ?
Auteur : Dr. Mark Bailey
Mark est un chercheur dans le domaine de la microbiologie, de l’industrie médicale et de la santé qui a travaillé dans la pratique médicale, y compris les essais cliniques, pendant deux décennies.
Source (en anglais) : https://drsambailey.com/covid-19/warning-signs-youve-been-tricked-by-virologists/








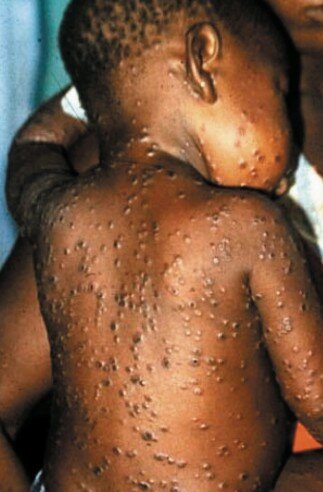
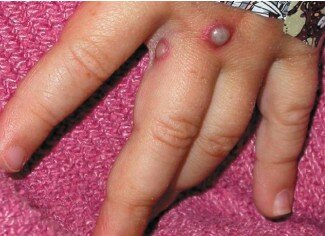
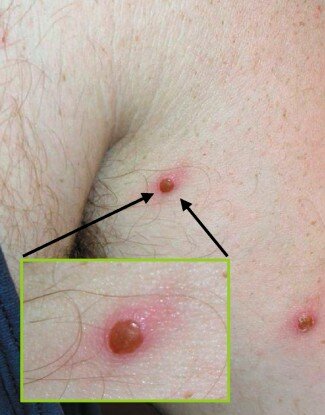



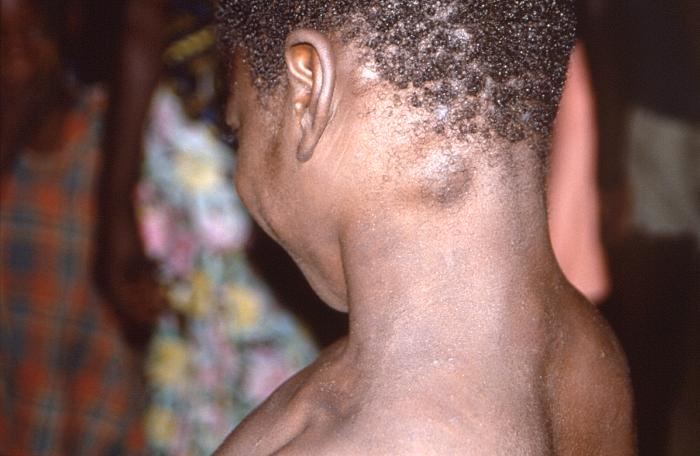






![Terrain Le Film – Documentaire Complet Partie 1 et 2 [VOSTFR]](/wp-content/uploads/2022/02/Terrain-le-film-cover2-1024x536.jpg)